监督学习
就是训练数据有标签的学习。
所谓监督学习, 就是两步, 一是定出模型确定参数, 二是根据训练数据找出最佳的参数值
正则化
正则化就是对参数施加一定的控制, 防止参数走向极端。
常用的正则化就是 L2 正则, 也就是所有参数的平方和。
tf-idf
TF-IDF(term frequency–inverse document frequency)用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加, 但同时会随着它在语料库中出现的频率成反比下降。
simhash
局部敏感 hash。
- 切词统计, 词, 权重
- 每个词 hash, 01 串, 01 串转为权重串, 1 对应正权重, 0 对应负权重
- 整片文章的权重串按位相加
- 转为 01 串, >0 位 1, 否则为 0
原理: 一个词在本文的权重高, 在相似度高的另外一篇文章中, 其权重也高, 那么它在构建 hash 的时候的贡献度也越高。
海明距离
二进制字符串的 a 和 b, 海明距离为等于在 a XOR b 运算结果中 1 的个数。
也就是二进制位值不同的个数。
余弦相似度
通过计算两个向量的夹角余弦值来评估他们的相似度。
一个简单算法公式。
决策树 decision tree
回归树 regression tree
随机森林 random foreast
各个决策树是独立的、 每个决策树在样本堆里随机选一批样本, 随机选一批特征进行独立训练, 各个决策树之间没有啥毛线关系。
boosted tree
提升树算法, 是一种: Regression Tree 回归树
简单描述。 都是特征(feature)到结果/标签(label)之间的映射
Boosted tree 最基本的组成部分叫做回归树 (regression tree)。
把输入根据输入的属性分配到各个叶子节点, 而每个叶子节点上面都会对应一个实数分数。 你可以把叶子的分数理解为有多可能这个人喜欢电脑游戏。 可以简单地把它理解为 decision tree 的一个扩展。 从简单的类标到分数之后, 我们可以做很多事情, 如概率预测, 排序。
xgboost
有监督的分类工具, 速度快
xgboost 是大规模并行 boosted tree 的工具, 它是目前最快最好的开源 boosted tree 工具包, 比常见的工具包快 10 倍以上。
分类和回归树 CART 树
fasttext
fasttext 是 facebook 开源的一个词向量与文本分类工具。 快速文本分类算法。
cbow 模型则是从上下文来预测一个文字。 上下文指的便是目标词周围的固定大小窗口中包含的单词包。
fastText 模型输入一个词的序列(一段文本或者一句话), 输出这个词序列属于不同类别的概率。
典型场景
- 有效文本分类 :有监督学习
- 学习词向量表征:无监督学习
不同于 word2vec, fasttext 利用的是词的形态学信息, 也就是词的内部构造信息, 也就是子词信息。 fasttext 采用的 character n-gram 来做的。
fastText 还加入了 N-gram 特征。 “我 爱 她” 这句话中的词袋模型特征是 “我”, “爱”, “她”。 这些特征和句子 “她 爱 我” 的特征是一样的。 如果加入 2-Ngram, 第一句话的特征还有 “我 - 爱” 和 “爱 - 她”, 这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。
fasttext 使用的分类的方法, 也就是根据与它计算 score 的另一个词是否是上下文来进行二分类, 具体用到的是 logistics 回归方法
word2vec
- 连续词袋模型 (CBOW):从上下文来预测一个文字
- Skip-Gram:从一个文字来预测上下文
上下文指的便是目标词周围的固定大小窗口中包含的单词包。
它把一个 word 映射到高维 (50 到 300 维), 并且在这个维度上有了很多有意思的语言学特性,比如单词”Rome”的表达 vec(‘Rome’), 可以是 vec(‘Paris’) – vec(‘France’) + vec(‘Italy’) 的计算结果。
cbow
将单词映射到向量的技术
skip-gram
向量距离
把每个人与所有其他人进行比较, 并计算他们的相似度评价值。 有两种方法:
- 欧几里得距离本质是求出两个向量的夹角。
- 皮尔逊相关度是对向量标准化(减去平均值)之后再求它们的夹角。
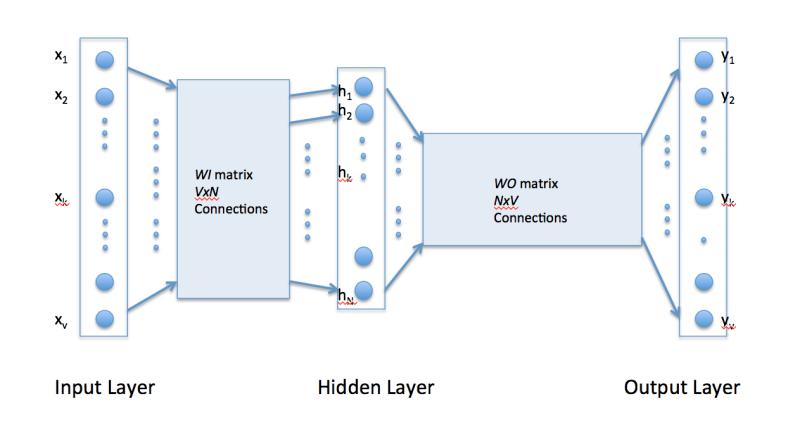
欧几里得距离
空间中两点的距离
把每个人对电影的评价当作一个多维空间中的向量。 两个人的相似程度就是两个向量的距离。
- 向量的维度就是电影名称
- 每个维度的值就是对这个电影的评分。
可以通过下面的函数计算两个人的相似度。 最后的返回值做了 Normalization, 保证返回 1 是完全相似。 返回 0 是完全不相似。
欧氏距离能够体现个体数值特征的绝对差异, 所以更多的用于需要从维度的数值大小中体现差异的分析, 如使用用户行为指标分析用户价值的相似度或 差异;
而余弦相似度更多的是从方向上区分差异, 而对绝对的数值不敏感, 更多的用于使用用户对内容评分来区分用户兴趣的相似度和差异, 同时修正了用户间可能 存在的度量标准不统一的问题(因为余弦相似度对绝对数值不敏感)
余弦相似度
两个 n 维样本点 a(x11, x12, …, x1n) 和 b(x21, x22, …, x2n) 的夹角余弦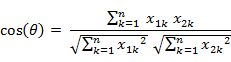
夹角余弦取值范围为 [-1, 1]。 夹角余弦越大表示两个向量的夹角越小, 夹角余弦越小表示两向量的夹角越大。 当两个向量的方向重合时夹角余弦取最大值 1, 当两个向量的方向完全相反夹角余弦取最小值 -1。
关于归一化: 因为这个公式可以变换,
- a/b * c/d == ac / bd
- ab/cd + ef/cd = (ab+ef)/cd
皮尔逊相关度
如果某个人评分总是比另外的人高, 欧几里得距离就不是那么合适了。 这个时候可以用皮尔逊相关度来计算两个变量的相关程度。
pearson 其实做的事情就是先把两个向量都减去他们的平均值, 然后再计算两个向量的夹角余弦值。
ctr
CTR(Click-Through-Rate)即点击通过率。 广告的实际点击次数除以广告的展现量。
最开始 CTR 或者是推荐系统领域, 一些线性模型取得了不错的效果。 比如: LR, FTRL。 无法提取高阶的组合特征。
比较完整的介绍
https://www.tinymind.cn/articles/3653
tensorflow
https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/
tensorflow 处理图像分类
https://tensorflow.google.cn/tutorials/images/image_recognition
k-means
k- 平均算法(英文: k-means clustering) 聚类分析方法
目的是: 把 {\displaystyle n} n 个点(可以是样本的一次观察或一个实例)划分到 k 个聚类中, 使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类, 以之作为聚类的标准。
knn
k nearest neighbor k 近邻
简单、 紧凑的算法。
需要分类号的训练集, 需要设定 k, 通过分析训练集, 获取分类向量中心点。 用于新 item 的分类。
多臂老虎机multi-armed bandit
多臂老虎机。
Bandit 算法是在线学习的一种, 一切通过数据收集而得到的概率预估任务, 都能通过 Bandit 系列算法来进行在线优化。
这个公式计算出的只是系统成功概率的最佳估计。
估计出一个置信度较高的概率 p 的概率分布。 怎么能估计概率 p 的概率分布呢?
答案是假设概率 p 的概率分布符合 beta(wins, lose) 分布, 它有两个参数:wins, lose。
每个臂都维护一个 beta 分布的参数。 每次试验后, 选中一个臂, 摇一下, 有收益则该臂的 wins 增加 1, 否则该臂的 lose 增加 1。
Thompson sampling 算法
用每个臂现有的 beta 分布产生一个随机数 b, 选择所有臂产生的随机数中最大的那个臂去摇。
以上就是 Thompson 采样, 用 python 实现就一行: (使用时)
1 | import numpy as np |
先验概率参数 alpha 和 beta。
PyMC 是一个实现贝叶斯统计模型和马尔科夫链蒙塔卡洛采样工具拟合算法的 Python 库。
深度神经网络
nn, cnn
HNSW 高维最近邻
从已知点构建图
- 途中每个点都有关联点
- 相近的点都互为关联点
- 途中所有连线的数量最少
朴素构造法
向图中逐个插入点, 插入一个全新点时, 通过计算“友点”和待插入点的距离来查找到与这个全新点最近的 m 个点(m 由用户设置), 连接全新点到 m 个点的连线。
查找过程
- 随机选一个点作为初始进入点
- 计算友点距离待查点 q 的距离
- 递归
优化查找
- 建立废弃列表,避免重复计算相同点
- 可以并行计算
跳表

分层结构, 目的是: 表层是“高速通道”, 底层是精细查找。

LSH 局部敏感哈希
海量高维数据如何快速查找相似: 近邻查找 或者 近似最近邻查找
LSH 是近似最近邻查找的一种, LSH 的基本思想是: 将原始数据空间中的两个相邻数据点通过相同的映射或投影变换(projection)后, 这两个数据点在新的数据空间中仍然相邻的概率很大, 而不相邻的数据点被映射到同一个桶的概率很小。
CTR
CTR: 点击率 点击数/曝光数。 CTR
CTR 预估: 基于模型计算, 估算一个广告被目标用户点击的概率, 用于选取最可能被点击的广告呈现给用户。
LR: 逻辑回归, 这个算法可以用于计算 CTR 预估。
特征: 影响广告效果的因素, 例如用户年龄, 性别, 手机机型
特征加工: 二值化, 交叉, 平滑, 离散化
离散化: 把不可比较的特征的取值离散成多个特征, 独立对待。
每个年龄一个特征,如总共只有 20 岁到 29 岁 10 种年龄,就把每个年龄做一个特征,编号是从 2 到 11(1 号是广告的反馈 ctr),如果这个人是 20 岁,那么在编号为 2 的特征上的值就是 1,3 到 11 的编号上就是 0。这样,年龄这一类特征就有了 10 个特征,而且这 10 个特征就是互斥的,这样的特征称为离散化特征。
交叉:
编号 12 的特征值不取 1,取值为该广告在男性用户上面的点击率,如对于男性 / 体育广告的组合,编号 12 的特征的值为男性在体育广告上面点击率,这样,编号为 12 的特征就变成了一个浮点数,这个浮点数的相加减是有意义的。
连续特征变理算特征:
因为特征值分布的特点各不相同,在不同的区间,应该考虑是不同的权重系数。对特征进行划分区间,每个区间为一个新的特征。离散化的特征能拟合数据中的非线性关系,取得比原有的连续特征更好的效果。
用户
广告
上下文
交叉 CTR
反馈 ctr
A=30 岁的用户点击匹克篮球的广告的点击率是多少
B= 男性的用户点击匹克篮球的广告的点击率是多少
知道这两个点击率, 还需要知道这两个点击率在评估这个人点击匹克篮球的广告的概率中分别起什么作用。 这两个点击率加起来不行, 相减也是不行的, 加权累加可能是一种办法, 但是这样行吗? 为了解决这个事情, 需要用模型来解决。 为了描述的方便, 我们把这两个点击率称为特征, 用一个向量 x=(x1, x2) 来统一表示。
其中 x 是上面的那个 x, w 也是一个向量, 表示的是 x 的每个特征的权重。 这个 w 每取一个值, 对相同的 user 和 ad 对就能得到一个预估的 ctr, w 同时也被称为是模型, 因为它能根据 x 的取值, 也就是特征的取值来决定 ctr。
机器学习领域的把这个训练过程称为是拟合分布的过程, 他们认为一次广告的展示是否被点击(每次展示被点击的概率可能不一样)是一个伯努利试验, 对多个用户展示多个广告的过程是一个伯努利过程, 总体的历史展示与点击数据符合一个伯努利分布, 伯努利试验成功的概率就是上面的 f(user, ad) 的值。
其中 y=1 表示这个展示被点击了, y=0 表示这个展示没有被点击。 似然函数和对数似然函数也可以写成下面的形式


求上面的式子的最大值, 就可以得到 w 的最优解, 这个最优解 w 就表示当前展示数据的伯努利分布是拟合的最好的, 用来预估 ctr 也是最好的。

回归
通过学习因变量和自变量之间的关系实现对数据的预测。
- 线性回归 y=wx+b 中找到 w 的可能值,使得 y 的误差最小,其中 x 是矩阵
- 逻辑回归 用来确定一个事件的概率,逻辑回归用于分类问题
回归中定义了损失函数或目标函数, 其目的是找到使损失最小化的系数。
逻辑回归
g(x)=1/(1+e^−x)
机器学习算法一般是这样一个步骤:
对于一个问题,我们用数学语言来描述它,然后建立一个模型,例如回归模型或者分类模型等来描述这个问题;
通过最大似然、最大后验概率或者最小化分类误差等等建立模型的代价函数,也就是一个最优化问题。找到最优化问题的解,也就是能拟合我们的数据的最好的模型参数;
然后我们需要求解这个代价函数,找到最优解。这求解也就分很多种情况了:
如果这个优化函数存在解析解。例如我们求最值一般是对代价函数求导,找到导数为 0 的点,也就是最大值或者最小值的地方了。如果代价函数能简单求导,并且求导后为 0 的式子存在解析解,那么我们就可以直接得到最优的参数了。
如果式子很难求导,例如函数里面存在隐含的变量或者变量相互间存在耦合,也就互相依赖的情况。或者求导后式子得不到解释解,例如未知参数的个数大于已知方程组的个数等。这时候我们就需要借助迭代算法来一步一步找到最有解了。迭代是个很神奇的东西,它将远大的目标(也就是找到最优的解,例如爬上山顶)记在心上,然后给自己定个短期目标(也就是每走一步,就离远大的目标更近一点),脚踏实地,心无旁贷,像个蜗牛一样,一步一步往上爬,支撑它的唯一信念是:只要我每一步都爬高一点,那么积跬步,肯定能达到自己人生的巅峰,尽享山登绝顶我为峰的豪迈与忘我。
另外需要考虑的情况是,如果代价函数是凸函数,那么就存在全局最优解,方圆五百里就只有一个山峰,那命中注定了,它就是你要找的唯一了。但如果是非凸的,那么就会有很多局部最优的解,有一望无际的山峰,人的视野是伟大的也是渺小的,你不知道哪个山峰才是最高的,可能你会被命运作弄,很无辜的陷入一个局部最优里面,坐井观天,以为自己找到的就是最好的。
LogisticRegression 就是一个被 logistic 方程归一化后的线性回归

这里θ是模型参数, 也就是回归系数, σ是 sigmoid 函数。 实际上这个函数是由下面的对数几率(也就是 x 属于正类的可能性和负类的可能性的比值的对数)变换得到的:

x1, x2, …, xm 是要考虑的因素。 把这些因素的得分都加起来, 最后得到的和越大, 就表示越喜欢。
θ1, θ2, …, θm 叫做回归系数。 我们需要用我们收集到的数据来训练求解得到它。
梯度下降 (gradient descent), 是利用一阶的梯度信息找到函数局部最优解的一种方法。

参数α叫学习率, 就是每一步走多远, 这个参数蛮关键的。
SVM 支持向量机
卷积
自动编码机
是一种无监督机器学习方法, 具有非常好的提取数据特征表示的能力, 它是深层置信网络的重要组成部分, 在图像重构、 聚类、 机器翻译等方面有着广泛的应用。
KD 树
高维数据的二叉树。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jaytp@qq.com

